ここではバイオインフォマティクス関連で登場する単語をご紹介します。
◆デオキシリボ核酸 (DNA)
◆リボ核酸
◆アミノ酸
◆タンパク質(protein)
◆ゲノム(genome)と鎖の向き
◆遺伝子(gene)
◆エクソン(exon)/イントロン(intron)
◆ORFとCDSとUTR
◆コドン(codon)
◆遺伝子の転写制御領域
◆モチーフ
・デオキシリボ核酸(deoxyribo nucleic acid)
遺伝情報の本体となる分子。DNAと略される。アデニン(A)、チミン(T)、グアニン(G)、シトシン(C)の4種類の塩基と、2-デオキシ-D-リボースからなる。一部のウィルスを除く全ての生物に存在し、リボース同士が結合した1本鎖のDNAが互いに水素結合であわさった2重らせん構造をとる。ただし、微生物よりも下等な生物は1本鎖構造を持つものがある。DNAが2本鎖を形成するときはAはTと、またGはCと対をなす構造をとる。従い、2本鎖の片側の塩基の並び方が決定されたら、もう片側の塩基の並び方は自動的に決定される。
鎖状に結合したDNAは化学的に安定した分子であり、制限酵素による消化反応を除いて生物が通常生存できる環境下では破壊されることは無い。このためPCR反応で複製して増やしたり、化学的に合成することが可能である。化学的に合成された数merから数十merの1本鎖DNAはオリゴDNAと呼ばれるが、慣習的に単にオリゴと呼ばれたりする。
実験や自動化された機械によって鎖上のDNAがどういう順序で並んでいるのかを決定することが出来るが情報的には上記のA、T、G、Cの4種しかなく、慣習的に「AGCTCTTTAGATTGC」といった文字列で情報を表記する。このため、鎖状のDNAの並び方を塩基配列と呼ぶ。塩基配列の長さを表すとき、1本鎖DNAを〜塩基(ベース、b)と表し、2本鎖DNAを〜塩基対(ベースペア、bp)と表す。例えば「AGCTCTTTAGATTGC」が1本鎖DNAなら15塩基(15b)、2本鎖DNAなら15塩基対(15bp)と表す。
・リボ核酸(ribonucleic acid)
DNAの情報を元にタンパク質を生産する際の遺伝情報の運び屋の機能を担う分子。RNAと略される。ただし、一部のウィルスではDNAの代わりに遺伝情報の本体としての機能を担う。アデニン(A)、ウラシル(U)、グアニン(G)、シトシン(C)の4種類の塩基と、D-リボースからなる。
構造的および機能的な差異からリボゾームRNA(rRNA)、メッセンジャーRNA(伝令RNA、mRNA)、トランスファーRNA(転移RNA、tRNA)に分類される。これらrRNA、mRNA、tRNAは化学的に不安定な分子である。また唾液や汗に含まれる分解酵素によって容易に分解されるため、RNAを扱う実験は高い精度が要求される。
・アミノ酸(amino acid)
タンパク質の材料となる分子。ただし、タンパク質に存在せずに単体で生物内の機能を担うものも存在する。分子内にアミノ基とカルボキシル基をもつものの総称であり、自然界では100種以上のアミノ酸が発見されているが、単一の生物のタンパク質の材料となるアミノ酸はその中の約20種のみである。後者のアミノ酸をαアミノ酸と呼び、通常はこちらをさす。
アミノ酸の種類の違いは側鎖の違いであり、その化学的な性質から親水性/疎水性、また塩基性/酸性の分類がされる。アミノ酸が数mer集まったもの(=短いもの)をペプチド、数十万〜数百万mer集まったもの(長いもの)をタンパク質と呼ぶ。
・タンパク質(protein)
生物の機能の本体となる分子。αアミノ酸を材料として生物の体内で合成される。合成されたタンパク質は構造としては1つ1つのアミノ酸が端から順番に珠数つなぎにつながった分子であるが、個々のアミノ酸のもつ電荷によって互いに水素結合を起こし複雑な立体構造をとる。タンパク質がもつ個別の機能はこの立体構造の違いで実現されている。非常に多くの種類と機能を担う分子であるが、生物の中の化学反応を触媒したり、生物体内の構造の材料になったり、生物体内の駆動部分になったりする。
・ゲノム(genome)と鎖の向き
ゲノムとは、生物一個体を形作る全ての塩基(DNA)情報の一セットをさす。例えばヒトゲノムといったとき、そのDNAの配列情報は、ヒトひとりを形作るための全ての情報のセットをさす。
ここで留意しなければならないのは、公的機関などによって解読され公開されているゲノム情報は、(2005年11月現在)あくまで解読に使った個体の情報に限られる。例えばそのゲノムがAさんのDNAを使って配列決定されていたとして、別のひとBさんとは細部が異なる。
ヒトゲノムの場合、DNAは2本の鎖状のらせん構造をしている。2本の鎖にはそれぞれ向きがあり、上流を5'側、下流を3'側とよぶ。ここで上流/下流と呼んでいるのは、遺伝情報をDNAから取り出すときに、情報の向きがあることを意味している。すなわち、上流側から下流側に向かって読まれるときに、DNAは意味を持つ。また、2本鎖はそれぞれ逆向きに並んでいる。強いて例えるなら、ヒトゲノムにおけるDNAの2本鎖構造は下り専用と登り専用のらせん階段がそれぞれ1本ずつからみ合ったような構造をしている。 慣習的に、染色体上の位置で言って一塩基目側に5'末端をもつDNAの鎖を+鎖(プラスさ)、染色体の終端側に5'末端をもつDNAの鎖を-鎖(マイナスさ)と呼ぶ。
・遺伝子(gene)
生き物の体の中では、タンパク質が様々な生化学反応を行って生命現象を支えている。ゲノム中で、タンパク質の情報を保有している領域を遺伝子(gene)と呼ぶ(図1)。遺伝子からタンパク質が作られるまでは、大まかに言って「遺伝子→[転写]→mRNA→[翻訳]→タンパク質」という流れをとる。左記カッコ[ ]内の用語は各段階を示す用語。

・エクソン(exon)/イントロン(intron)
ヒトなどの真核生物は、遺伝子の中でもmRNAになる部分とならない部分がある。mRNAになる部分をエクソン(exon)、mRNAにならない部分をイントロン(intron)と呼ぶ。エクソン/イントロンは5'側から連番で採番され、「○○遺伝子の第1エクソン」などと呼称したりする。(図2)

・ORFとCDSとUTR
ヒトなどの真核生物は、mRNAになる部分の中でもタンパク質になる部分とならない部分がある。タンパク質になる部分を翻訳領域と呼び、ORF(Open Reading Frame)と略される。このORF上の全塩基配列はCDS(Coding Sequence)と呼ばれる。
また、タンパク質にならない部分は非翻訳領域とよばれ、UTR(Untranslated Region)と略される。第1エクソン上の5'側に非翻訳領域がある場合5'-UTR、最終エクソン上の3'側に非翻訳領域がある場合3'-UTRと呼ばれる。(図3)

・コドン(codon)
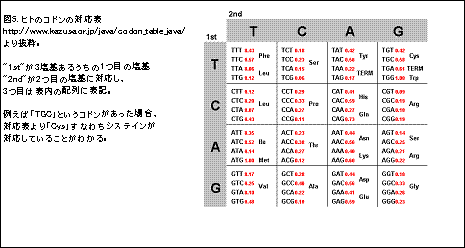
タンパク質はアミノ酸がつながったものである。生き物の体の中でmRNAからタンパク質を作るとき、3個のRNAで1個のアミノ酸に対応する。RNAとDNAの対応関係は1対1であるので、1個のアミノ酸情報を遺伝子上のDNA3個で表していることになる(図4)。この1個のアミノ酸を表す3塩基の組をコドンと呼ぶ。

コドンの組み合わせは生き物ごとに違うが、同一の生き物同士(ヒトならヒト同士)では、おなじ対応付けがされる。この塩基とアミノ酸の対応関係を示した表を、コドンの対応表とかコドン表などと呼称する(図5)。
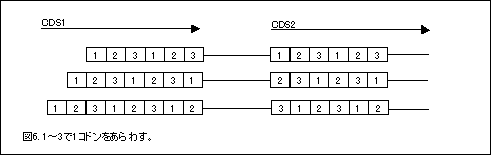
一方CDSはexonなどと同じように遺伝子の5'側から連番で採番されている。CDSのコドンについて考えてみると、CDS1のはじめの1塩基目は必ずコドンの1塩基目が対応している。ところが、CDS2から最終CDSまでは、exon/intronの切れ目が遺伝子ごとに違うため、かならずしもコドンの1塩基目と対応しているわけではない(図6)。したがって、第2CDS以降の配列を考えるときは、そのCDSがコドンの何番目の塩基からはじまるかを考慮する必要がある。
・遺伝子の転写制御領域
遺伝子からmRNAが作られるタイミングは、「ある日あるときたまたま作られる」という訳ではない。各遺伝子の5'側の領域には、特定のタンパク質が結合する領域がある。その領域に「mRNAを作成し始めなさい」という指示をするタンパク質が結合することがトリガーになり、mRNAが作られる。
このmRNAの転写を制御しているタンパク質が結合する領域を、転写制御領域と呼ぶ。転写制御領域は遺伝子ごとに違っており、遺伝子の5'側の上流数百から数千塩基の中に存在すると考えられている。(図7)
![]()
・モチーフ
生物の体の中でタンパク質は様々な機能を担っているが、その機能はタンパク質の立体構造(三次元構造)により異なる。タンパク質の立体構造はタンパク質ごとに異なり、1つのタンパク質としてみたときは、似た機能をもつ別の遺伝子から作られるもの同士でも、立体構造がまったく異なっていたりする。
ところが、似た機能を持つタンパク質を部分ごとに見た場合は、共通性が認められる場合がある。身近な例に例えれば、自動車は車種が違えば外観は変わってくるが、おなじ生産者の共通のサイズの自動車ではシャーシを共用していたりする。
上記のような、部分ごとにタンパク質を見たときに他のタンパク質でも共通の構造が取る個所はモチーフと呼ばれ、公共DBなどで管理されている。このモチーフは、タンパク質の構造が似通っている個所であるから、その元となっているDNAの配列も似ている場合が見られる。従い、実験で機能や構造が調べられていないタンパク質でも、塩基の配列データを既存のモチーフのものと比較することで、機能を推定していくことができる。